- Structure of the NDT Unified Views
- Example - Custom unified view to explore WScale
- Future-proofing Your Custom Unified Views or Subqueries
NDT Unified Views and the statistics pipeline are optimized to provide researchers curated data to optimally support studies of the evolution of Internet performance organized by geopolitical boundaries.
In this document we describe how to create Custom Unified Views to efficiently address alternative research questions.
Structure of the NDT Unified Views
Unified views are are built on extended views, which are a maximal presentations of all M-Lab raw data: every measurement (raw row) is annotated with everything we know about the data, including filter flags, Geo labels, etc.
The Unified Views are a UNION of selected fields from all three NDT data types, with a filter applied to only present completed, valid test results according to our current, best understanding. Unified views can be customized to provide different data by simply replacing the last processing step with different filters.
Processing Steps in the Production of NDT Unified Views:
The very last steps of the Measurement Lab data pipeline are as follows:
- Precursor - The extended views contain every row and every column
- Filter columns to a standardized subset (top level structs make this easier)
- Union across data sets (columns must have exactly matching types)
- Filter rows using filter flags that were computed in some earlier step
If you open the NDT Unified Download View in the BigQuery console measurement-lab.ndt.unified_downloads and open the Details tab, and you will see something like this:
SELECT * EXCEPT (filter)
FROM (
-- 2020-03-12 to present
SELECT id, date, a, filter, node, client, server,
FROM `measurement-lab.intermediate_ndt.extended_ndt7_downloads`
UNION ALL
-- 2019-07-18 to present
SELECT id, date, a, filter, node, client, server,
FROM `measurement-lab.intermediate_ndt.extended_ndt5_downloads`
UNION ALL
-- 2009-02-18 to 2019-11-20
SELECT id, date, a, filter, node, client, server,
FROM `measurement-lab.intermediate_ndt.extended_web100_downloads`
)
WHERE filter.IsValidBest
The Unified Upload View is similar.
If you have your own GCP project, you can click copy view and edit it there as a view.
Most people will want to copy and edit this view as a subquery of a larger research query. To do this copy or cut and paste the SQL from MLab’s unified view from the Details tab to the query editor.
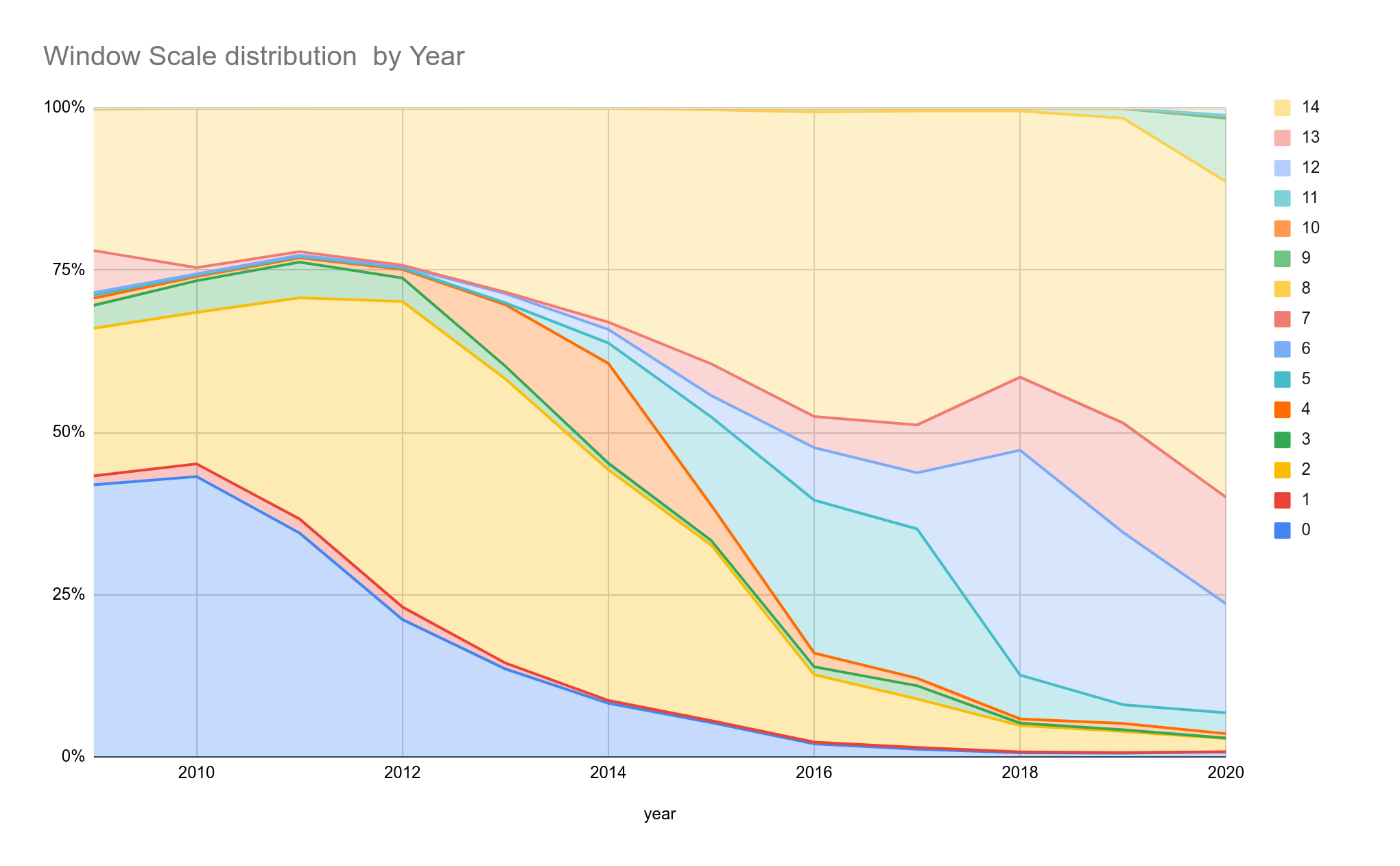
Example - Custom unified view to explore WScale
Note that this example includes subexpressions to standardize the encoding of the WScale column and WHERE clauses to eliminate rows with invalid values.
# Tabulating Window Scale by year
# Part 1, a subquery that defines CustomUnifiedView, with an additional
# WScale column.
WITH
CustomUnifiedView AS (
SELECT * EXCEPT (filter)
FROM (
-- 2020-03-12 to present
SELECT id, date, a, filter, node, client, server,
_internal202010.lastsample.TCPInfo.WScale & 0xF AS WScale
FROM `measurement-lab.intermediate_ndt.extended_ndt7_downloads`
UNION ALL
-- 2019-07-18 to present
SELECT id, date, a, filter, node, client, server,
_internal202010.S2C.TCPInfo.WScale & 0xF AS WScale
FROM `measurement-lab.intermediate_ndt.extended_ndt5_downloads`
WHERE _internal202010.S2C.TCPInfo.WScale IS NOT NULL
UNION ALL
-- 2009-02-18 to 2019-11-20
SELECT id, date, a, filter, node, client, server,
greatest (_internal202010.web100_log_entry.snap.SndWindScale, 0) AS WScale
FROM `measurement-lab.intermediate_ndt.extended_web100_downloads`
# 3 corrupted values in 2017
WHERE _internal202010.web100_log_entry.snap.SndWindScale <= 14
)
WHERE filter.IsValidBest
),
# Part 2, a research query that tabulates WScale by year.
# The remaining part of this query is one example of a research query using the above custom
# "unified view" as expressed in a sub-query.
SELECT
EXTRACT(year FROM date) AS year,
WScale,
COUNT (*) AS tests,
FROM CustomUnifiedView
WHERE date > '2009-01-01'
GROUP BY year, WScale
ORDER BY year, WScale
Future-proofing Your Custom Unified Views or Subqueries
All columns outside of the documented standard columns in unified views are subject to future changes. If a column name starts with an underscore, we already have plans to change it. If the name also contains something that looks like a date code or version tag, the column (or structure) is explicitly temporary and likely to be updated frequently as we evolve the underlying schemas.
To future proof custom unified views, researchers are strongly encouraged to maintain clean separation between data grooming in their custom unified view, and their research logic in subordinate queries. All of the columns presented by the custom unified view should be standardized either by the researcher themselves or by following MLab standard views.
Note that we plan to overhaul the row filtering logic in the future.
Researchers are encouraged to monitor and track changes to published unified views.
If the separation is done well, researchers can track future changes to M-Lab’s schema with single line changes to their custom unified views, for example to update a column name or location within the schemas.